I’ve used H2O for about 2 years on a medium scale, over 500 million rows of data, in the prediction of advertisements on the internet. I’ve never used paid support, or a paid version, just the open source/free to use version. But in short, I love it. H2O is one of my favorite machine learning projects, I’ve used it in a few Kaggle competitions too and done pretty well with near default settings. So I’ve wanted to write about using it and how just about anyone can use it to do advanced and accurate prediction.
In this walkthrough I’m going to show you how to predict house values from a tsv (tab separated values) data file I made with 20 houses, their sizes, and other features. We’re going to see how to import and produce a model for predicting house values based on this spreadsheet.

H2O Overview
The Good
- Scales fairly easy. I’ve never used it with Spark, but they machines cluster together fairly easy.
- Easy to use. With about 60 minutes of training I’m fairly confidently I could teach anyone proficient in excel to use it.
- Includes a beautiful web based interface for quick and dirty analytics and predictions and visual inspection.
- Good accuracy without a lot of tuning
- Lots of algorithms. Many other packages only focus on one but they have many and it’s easy to test them all out with your data.
The Bad
- Java. Not a huge fan, H2O under Java uses more ram for like to like predictions & data size than other non java packages.
- Smaller community. It’s company backed but there’s a smaller group of people using it.
Supported Algorithms
- Generalized Linear Models (GLM) – regression
- Random Forest
- Gradient Boosting (GBM)
- K-Means
- Anomaly Detection
- Deep Learning
- Naïve Bayes
I’m just going to walk you through a simple prediction model end to end. There a few different ways to actually use H2O but i’m only going to cover the web based interface here. Perhaps in a later tutorial I’ll do more but the web interface will let you see how powerful and easy it is.
Prerequisites
- Java Virtual Machine
- Sample data file (download and save this to your local computer)
- h20
- Any linux/mac with 2-4 gigs of ram or so should be fine. Windows might work but i’ve never tried. You don’t need a server to do this, your desktop will work fine.
Installing H2O
After you download the H2O zip file, you’ll want to open up a command line. Unzip it, and run it with the java command, as follows. You don’t have to actually install anything.
cd ~/Downloads unzip h2o-3.10.0.10.zip cd h2o-3.10.0.10 java -jar h2o.jar
That last command will start the H2O server up. The entire application runs from that command. It also will start up a local web server – it should by default be running on port 54321. If you already have something there it will pick another one and you’ll want to look at the output of the application.

Open your browser and go the url that was output and you’ll get to a page that looks like this:

Go to “import files”, you can also get here anytime from “Data” menu as below.


Find the file you downloaded “housing_data_prediction.csv” in prerequisites above and click “import”. It will look something like this below. The import search/find files is a bit awkward, unlike others you’ve used online you’ll need to find the folder, not the file, then click the magnify glass, and click the + sign next to the file you want to import, then “import” button. It will look like this:
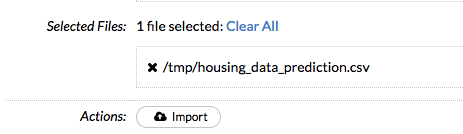

Next step, click “Parse these files…” and it will process and bring up the data summary view. In this view it will show you the data types it guesses the columns are. It looks as sum or all of the data to guess the type. Luckily, it guessed all of data column types correct for the sample file I made. Real numbers like house values, square feet, number of bathrooms are all numeric data types. Columns like has_pool, where the value can be yes/no or even a list of items, like main_flooring_type, is to be considered an enum or bool for true/false, on/off, yes/no type questions. Picking the correct data type per column is crucial to getting the model right.
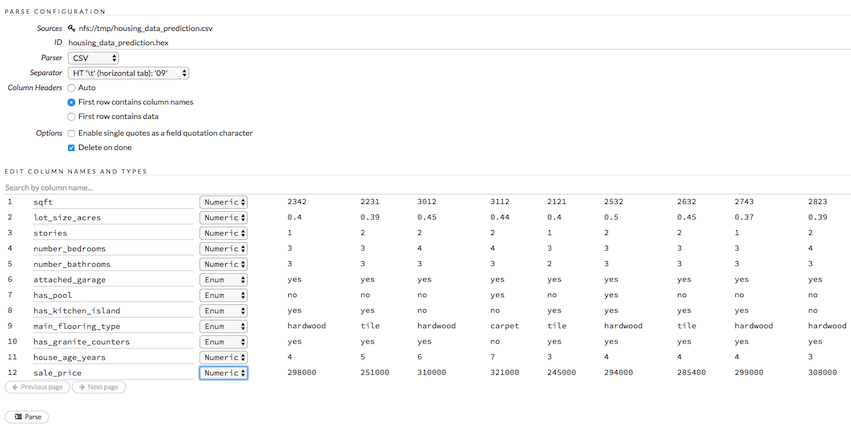
Next, click “Parse”, the file is small so it should run nearly instantly, then click “View”.

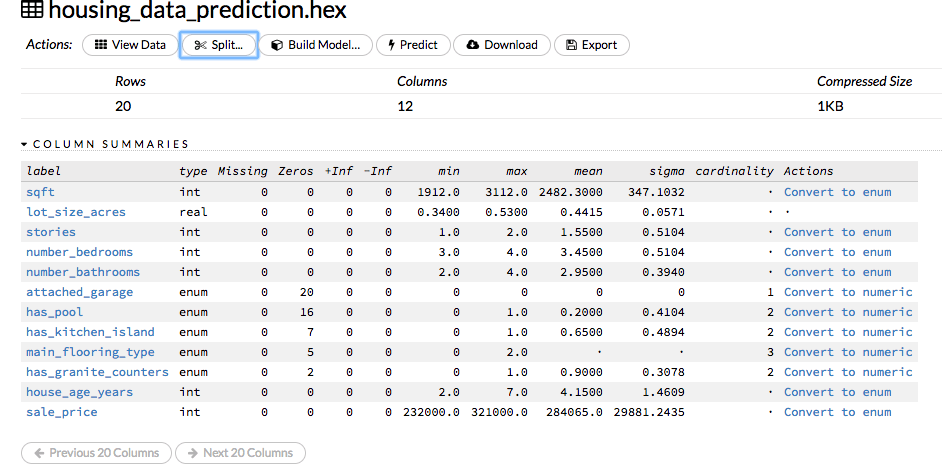
You should be looking at a screen like this one, giving you some basic statistics about the file. Cardinality is for enums, describing the # of unique values. Interesting to note, that attached_garage only has 1 value since all of the homes in the file have that. I’m not optimizing here, but in real work scenarios you’d want to ignore columns like that as they add no value and only complicate the model there for reducing accuracy. Machine learning is all about making the most accurate “generalizations” as possible, so removing worthless features is always ideal.
What we’re going to do next is split the data we just uploaded into 2 random files. H2O call’s these frames, which is basicly a preprocessed data file. So to do that we click “split”, it will bring up this screen and were going to do a 75/25 split, which seems to be the default here as well. That will split the frame “housing_data_prediction” into 2 frames, one with 75% of the rows (randomly assigned) and one with 25% of the rows.

Click “Create”. After that’s done processing you can go to the top menu, Data->List All Frames and you should see a screen listing out all the data frames the system now knows about. The frame_25%, frame_75%, and the original file, housing_data_prediction.

Now click “Build Model” on the 75% frame file. We’re doing this only on the 75% file because we want the model to not know about the 25% because we’re going to try to predict the house values in 25% file from the 75% file.

Even though I used the 75% file as the training data, I went ahead and left the 25% data as the validation data. This is not ideal for real world, but I did it anyways because this data file is so small it needs some help. The validation frame helps the model course correct as it’s building, making sure it’s on the right path. I left nearly all settings the default, I’ve found most of the default values for H2O to work fairly well, they seem to have put a lot of thought into it. Make sure to pick the correct “response column”, which is the column that you’re trying to predict, in this case its “sales_price”. You’re telling the model here that given these features, this is the expected response. If you really wanted, you could also try to predict the size of the house, or if it had a pool or not. Pretty cool huh? But you’d need a lot more data on those to get any accuracy.
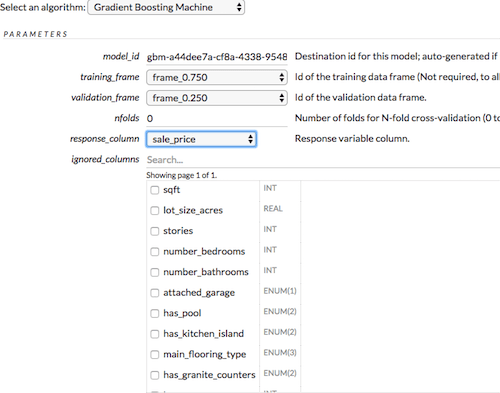
It did through me an error for not having enough rows, so i adjusted the min rows in setting here to 5.
![]()
You’ll then click “Build Model”, it will run for a bit, with such a small file it should be quick, nearly instant, but with more data say hundreds of thousands or millions of rows it could take hours. Then click “view” after the model is done building and you’ll see the summary of the model build results.

Analyzing the Results
Variable importance, these are, well important. You can see that the #1 most important factor in predicting the value of a house, according to our model, is the size of the house. Makes sense, stories and number of bedrooms are also important, but not nearly as much as sqft. Variable importance is not saying more is better, just that the column is useful for predicting value, it could actually be inverse.
Accuracy
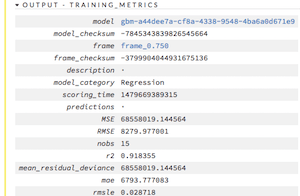
- r2 – closer to 1 this is, the closer the data fits the model. ours is .91, which is pretty good.
- RMSE – root mean squared error, 8279, so looks like we’re off on average around 8k per prediction.
Prediction
To do the prediction based on our new model we want to go to top menu, Score->Predict…
That will bring up a menu like this, make sure you’re predicting on the 25% data frame using the model, auto named something similar to what we’re showing here, then click “Predict”
After that prediction runs, you’ll see a screen like this one. We want to combine the predictions with the original file so we can compare the results. To do that we’ll click “Combine predictions with frame” this will put the predicted house value in a new column in combined data frame.
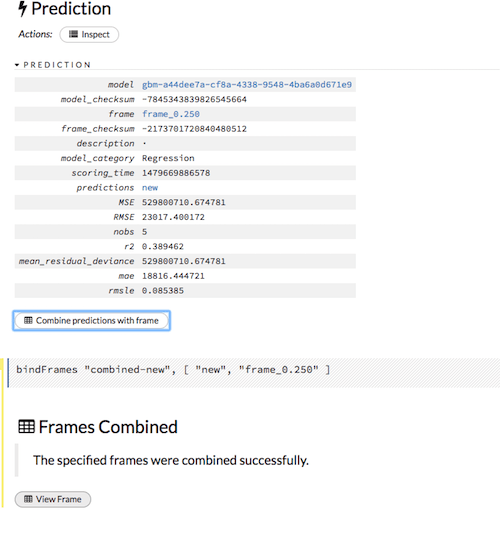
Next, click “View Frame” and you can “Download” the results into a CSV which I viewed in excel.
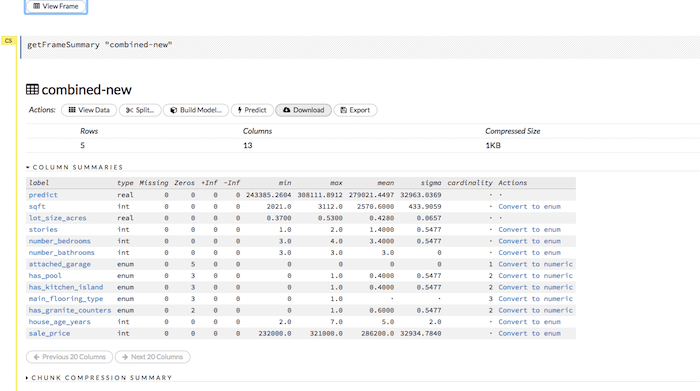
Results
Here are the results in a CSV. The 1st column is our new model’s prediction for the house value, and on the far right is the actual price the house sold for.

Summary
So you can use these same techniques to predict just about any kind of data with H2O, from house values like Zillow, or credit card fraud, click fraud, anything as long as you get the right feature data, which is typically the most difficult part in machine learning. You can also play around with different models, like deep learning, random forest, regression (glm). You’ll find different data works better with certain types of models. Machine learning typically requires a TON of data. The more the better. You can always trim it down later. You’ll also want to look at feature mining, which is taking something like a date the house was built, and turning it into how many years ago it was built. Something more useful for prediction which you can measure with variable importance. Or taking the user agent from a browser and breaking it into useful parts say the operation system, instead of a long string. For credit card fraud, you’d need features like, average user transaction size, and zip code, turn that into how far from home someone was when the transaction occurred.
Good luck!